📌 TL;DR
Aprende a implementar una arquitectura RAG (Retrieval-Augmented Generation) utilizando la feature nativa Gemini File Search de Google y n8n como orquestador. Evita construir infraestructuras complejas con bases de datos vectoriales (como Pinecone) y descarga la responsabilidad del chunking, embedding y retrieval en el LLM directamente a través de llamadas API.
📑 Tabla de contenidos
- ¿Para quién es este tutorial?
- Arquitectura: RAG Nativo vs Tradicional
- Lógica del Pipeline (n8n Workflow)
- Trade-Offs del Sistema
- Preguntas frecuentes
¿Para quién es este tutorial?
- Ingenieros de Datos y AI Developers implementando sistemas RAG simples.
- Desarrolladores Low-Code expandiendo capacidades LLM mediante n8n.
- Prerrequisitos: Conceptos de APIs REST, autenticación API Keys de Google AI Studio y el funcionamiento de n8n HTTP Request Nodes. Si no tienes claro el concepto de API, revisa primero nuestra guía sobre la anatomía de una aplicación web.
Arquitectura: RAG Nativo de Google vs Tradicional
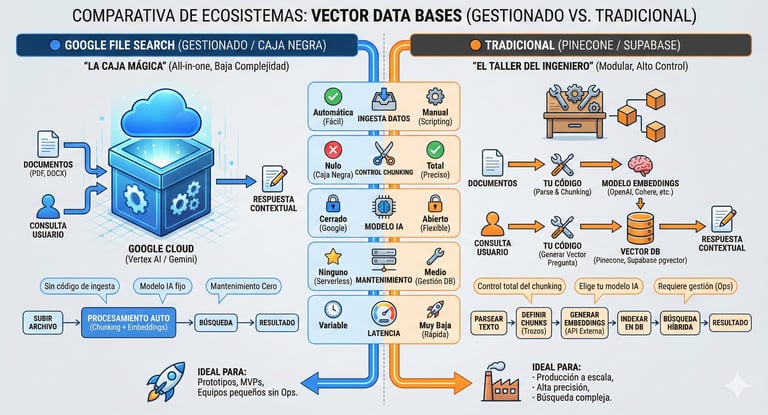
En el RAG tradicional, el pipeline requiere chunking de documentos (LangChain/LlamaIndex), generación de embeddings (ej. text-embedding-3-small) y despliegue de un almacén vectorial (Pinecone, Supabase/pgvector). El File Search de Gemini delega todo este proceso automatizado a la infraestructura de Google: envías el binario vía API, generas un vector_db lógico de Google y vinculas su ID al array de Tools del prompt.
Lógica del Pipeline (n8n Workflow)
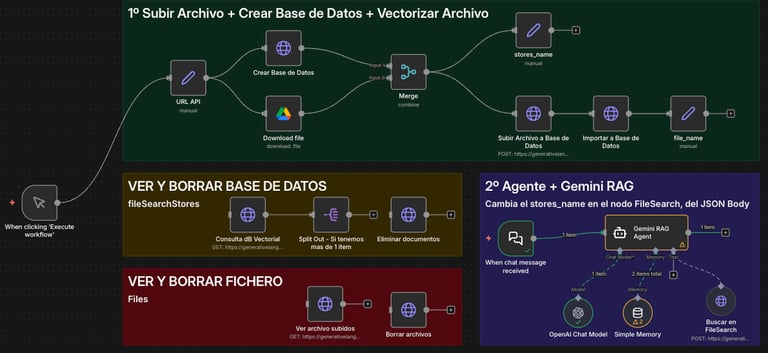
La orquestación asíncrona en n8n se divide en dos fases lógicas u operaciones CRUD:
- Ingesta (ETL/Almacenamiento Directo): Blob Request ➡️ API
Create Store➡️ APIUpload binary➡️ APILink Store. - Retrieval Tool-Calling (Agent Node): Front-end Chat Node ➡️ N8n AI Agent Node (Llama a Gemini inyectando el
Store IDreferenciado).
Fase 1: Tubería de Ingesta (Backend)
Este workflow toma el blob binario y finaliza exponiendo un hash de Store_ID de indexación a n8n.
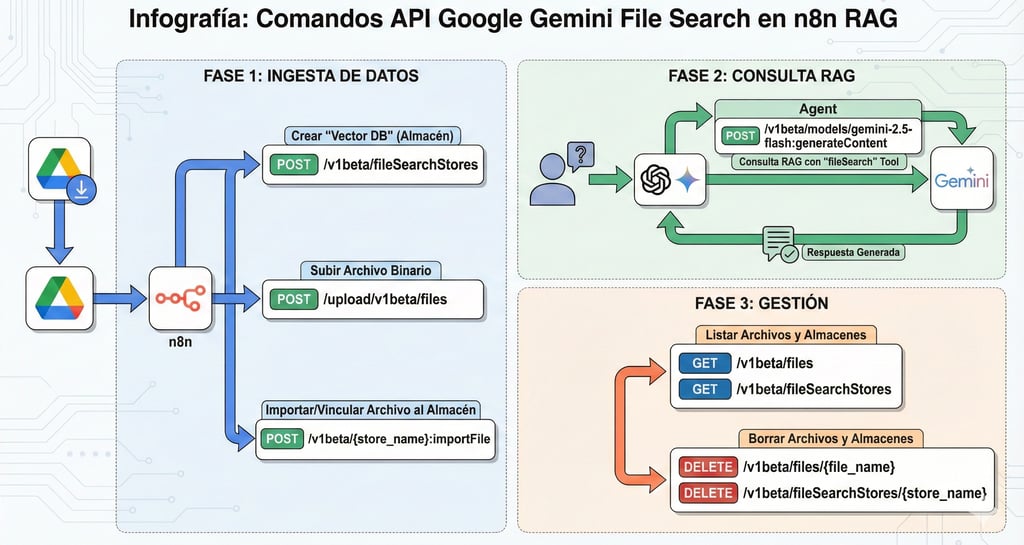
1. Descarga del Payload
A través de nodos de red nativa (Drive, Webhook POST), descargamos el documento crudo a la memoria del contenedor de n8n (blobs o binarios temporales).
2. Generación del Store Puntero
Ejecutamos una petición HTTP POST al endpoint nativo de Gemini /v1beta/fileSearchStores pasando el header de Authorization con la API key. La respuesta de Google devuelve la key identificativa name (ej: fileSearchStores/123xyz).
3. Upload Async de Archivos a la API de Google
Lanzar la inserción de datos require 2 peticiones REST encadenadas:
- Fase Upload:
POSTasíncrono sobre el endpointupload/v1beta/filescargando el binario en formato MultipartForm (mimeType: application/pdf). La red de Google te devolverá un identificador único (file_uri). - Fase Import (Vincular Store vs File): Tarea condicional en
merge nodeque asegura que el URI y el StoreID estén calculados para lanzar un POST final y adjuntar ese file_uri en particular a la bolsa de documentos en el IDfileSearchStores/123xyz.
Fase 2: Frontend Client de Inferencia
Con el índice construido en background en los servidores de Google AI Studio, solo necesitamos habilitar el Tool Calling explícitamente durante nuestras consultas (Inference stage).
La Herramienta HTTP Request Custom (Integración Gemini Tool)
La llamada Inference debe ejecutarse contra models/gemini-1.5-flash:generateContentusando Payload JSON (o chat/completions si usas OpenAI format support). Se inyecta el ID del file object al array tools nativas de Gemini y activamos la feature fileSearch.
{
"contents": [{
"parts": [{ "text": "Resume los puntos operativos del último trimestre: {{ $json.chatInput }}" }]
}],
"tools": [{
"fileSearch": {
"fileSearchStoreNames": ["fileSearchStores/TU_STORE_ID_GEBERADO"]
}
}]
}
Trade-Offs del Sistema
| Vector | Pinecone / Vector DB (PgVector) | Google Gemini File Search |
|---|---|---|
| Costes Fijos Infraestructura | Facturado por índices en base de datos dedicada ($) | Totalmente Gratis. Computado intrínseco dentro de Google AI Quota |
| Control de Parsing (Chunking) | Control ultra-granular con LlamaIndex Node Parser | Opaco, pipeline "caja negra" manejada por el motor cerrado de Google |
| Despliegue Back-end | Demanda scripts DevOps largos / Dockerizaciones de BD | Integración Serverless Low-Code pura 100% Request HTTP |
Preguntas frecuentes
¿Qué es un sistema RAG?
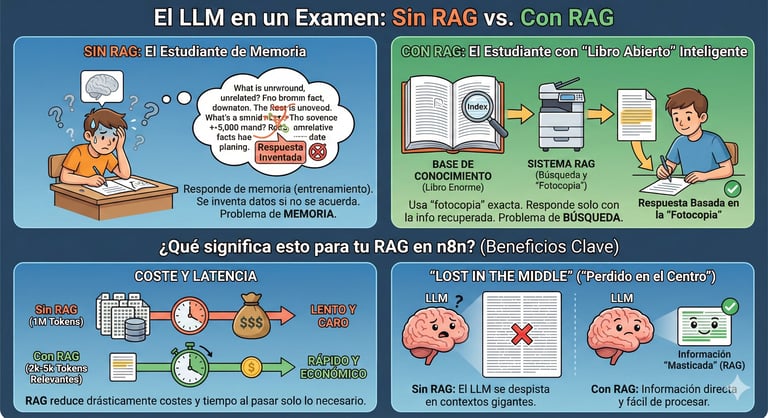
RAG (Retrieval-Augmented Generation) es una arquitectura que combina un LLM con una base de conocimiento externa. En vez de responder solo desde su entrenamiento, el LLM busca información relevante en documentos específicos antes de generar su respuesta. Esto reduce drásticamente las alucinaciones y permite al modelo responder con datos actualizados y específicos de tu empresa.
¿Necesito una base de datos vectorial para RAG?
No necesariamente. El approach tradicional (Pinecone, pgvector, Weaviate) te da control granular sobre el chunking y los embeddings, pero requiere infraestructura compleja. Google Gemini File Search ofrece una alternativa "serverless" donde subes los archivos y Google gestiona internamente todo el pipeline de indexación. Es ideal para MVPs y proyectos con presupuesto limitado.
Conclusión del Endpoint RAG
La adopción del Tool Calling Nativo y Files API encapsula toda la engorrosa lógica de chunking de bases vectoriales, aliviando la carga al servidor Backend (Node/N8n) y minimizando drásticamente la barrera de "Time-to-market". Su patrón Cloud reduce complejidad al escalonar proyectos MVPs (Minimum Viable Products) corporativos que solo buscan interacciones con PDF.
Si este tutorial te ha resultado útil, te recomiendo explorar cómo automatizar más procesos empresariales con IA, o profundizar en las herramientas de Vibe Coding para construir la interfaz de tu sistema RAG. Si necesitas ayuda implementando un RAG en tu empresa, hablemos.